A convolutional neural network is an artificial neural network where each neuron looks only at PART of inputs from previous layer.
In terms of image processing, each neuron in hidden layers will “look” at small local patterns of the image (such as edges, corners, and textures). We say that the in the initial layers of a CNN, the receptive field is relatively small.
But across the layers, its receptive field is expanded, learns to combine those low-level features into progressively higher level features, and eventually entire visual concepts such as faces, birds, trees.
Process
Process
Reference from machine learning development process
Link to original
- Get data
- Build a neural network
- Type of Layers
- Number of neurons in different layers
- activation function
- Train a neural network
- Specify loss
and, subsequently, cost function - Select optimization techniques, such as ADAM optimzer
- Fit the model with training data
- Minimize the average cost across data using backpropagation: We take small steps in the direction of steepest descent
Terms in Flow
Rough hierarchy and flow
- Input Layer
- Hidden Layers
- Convolutional layer
- Channel: stack of filters
- Filter: set of kernels
- Kernel: matrix of learnable weights
- Pooling layer
- Fully connected layer
- Classification, regression, other tasks
- Output Layer
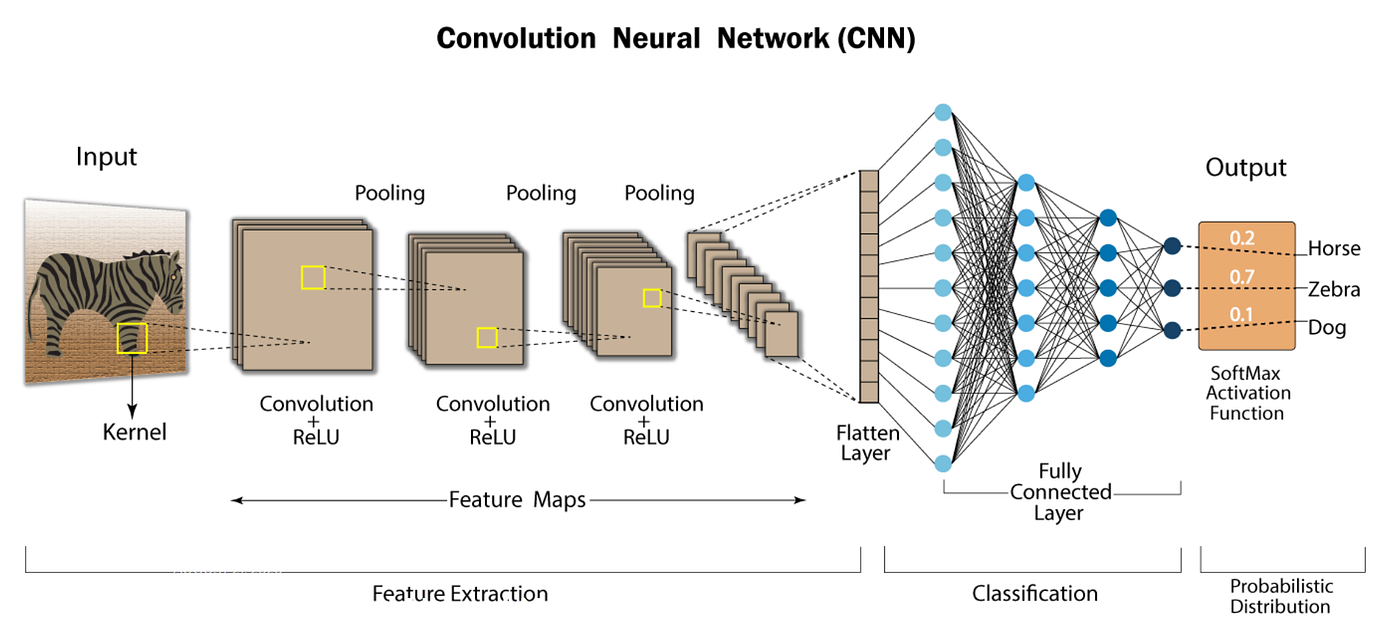
The typical flow: passing the input data through multiple layers, where each layer, especially convolutional layers, uses filters (each a different set of kernels) to extract features. These features are represented in separate channels, and the final output may be the result of classification, regression, or other tasks based on the learned features.
Input
The input is the initial data or image that is fed into the CNN. In the context of an image, it consists of pixel values arranged in rows and columns. For a color image, it typically has three channels (Red, Green, Blue).
Convolutional Layer
Channel (feature map): A two-dimensional array that represents the response of a specific filter applied to the input data (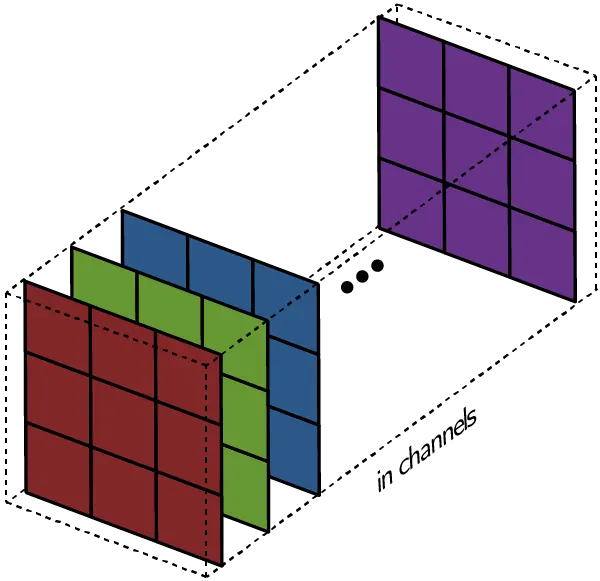
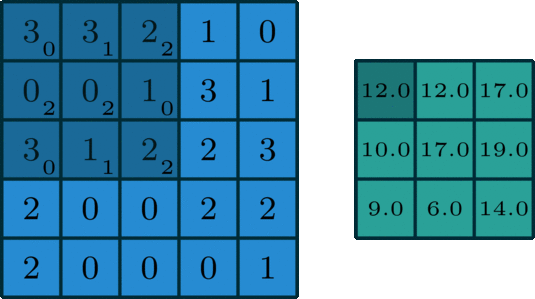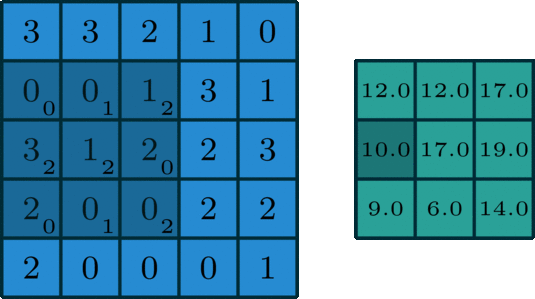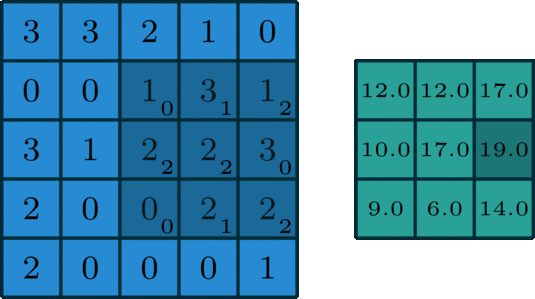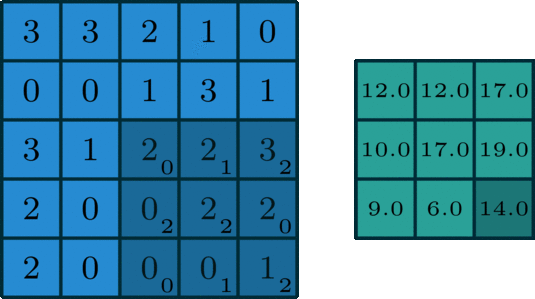
Kernel: Small, often square, matrix of learnable parameters (weights) used to perform convolution operations on input data. In the example below, it’s the dark blue, sliding matrix; learnable weights are written in subscripts. Notice two important points:
- Some weights are 0: This image kernel only activates (learns) specific region of the input data ➡️ visualization
- Some weights are shared/tied to reduce the number of parameters to optimize, because
- neighboring pixels in the image are related
- the same patterns (edges, textures, etc) can appear multiple times in an image
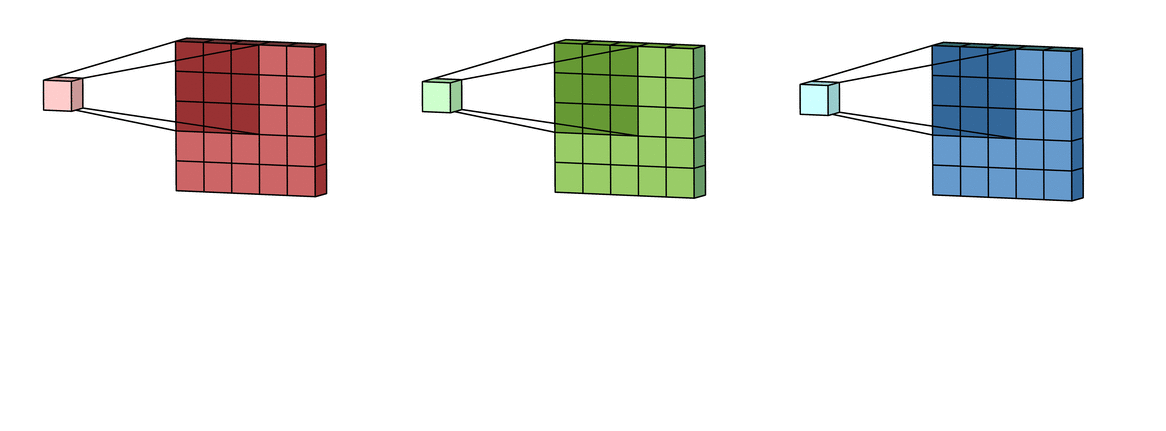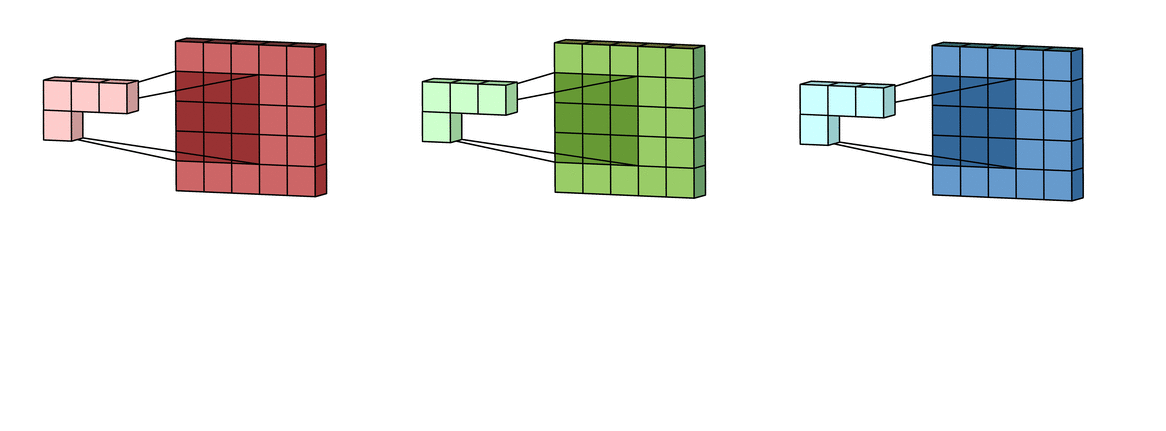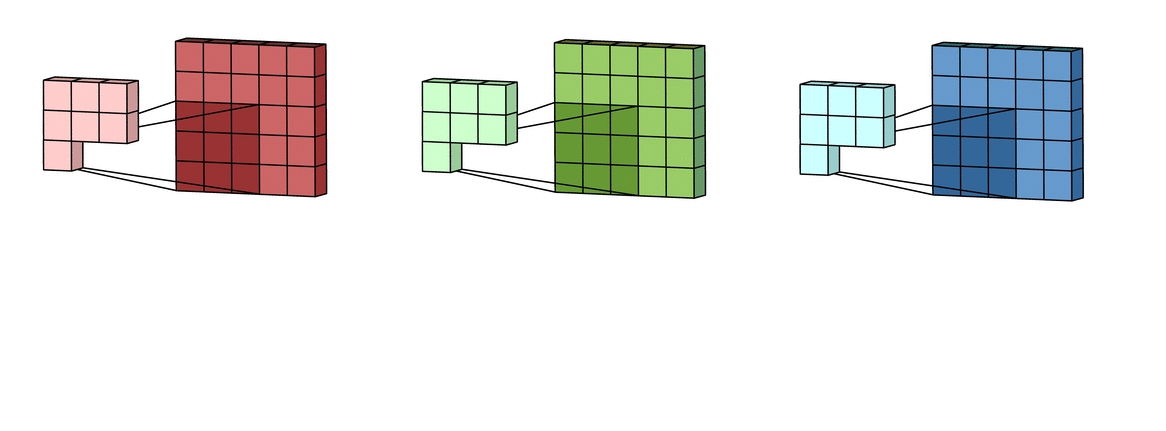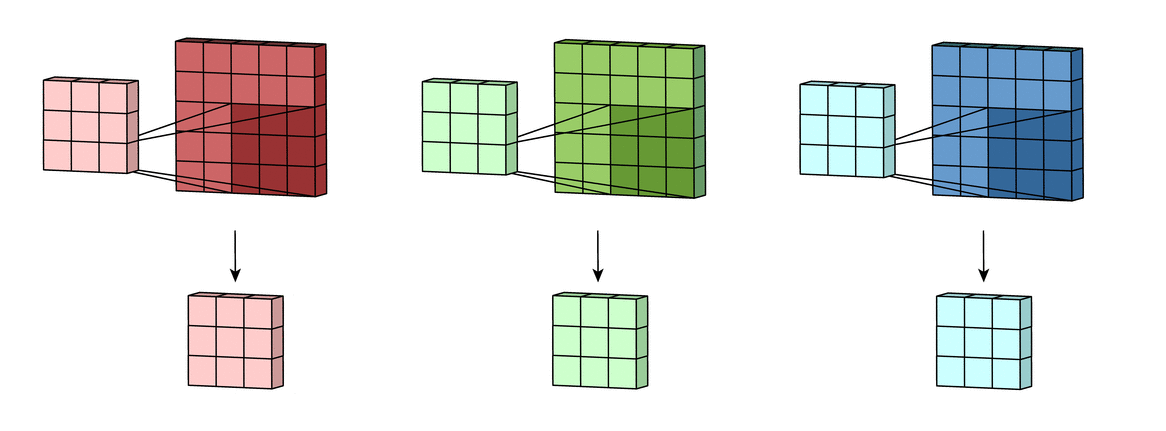
Filter: A collection of kernels to extract features from the input data. Each of the kernels of the filter “slides” over their respective input channels, producing a processed version of each.
Why "filter" name?
Intuitively, because we only focus on some local regions of the input, ignoring others. Technically, a filter is a collection of kernels, the sparse matrix of weights, with some weights are 0. Multiplying this sparse matrix with the input matrix will activate/highlight some regions and ignore some others (by turning them into 0).
Each of the per-channel processed versions are then summed together to form one channel. The kernels of a filter each produce one version of each channel, and the filter as a whole produces one overall output filter.
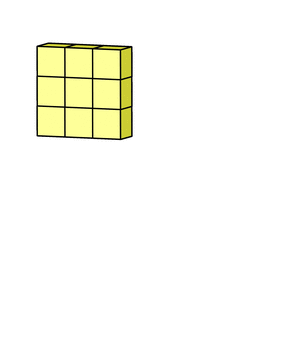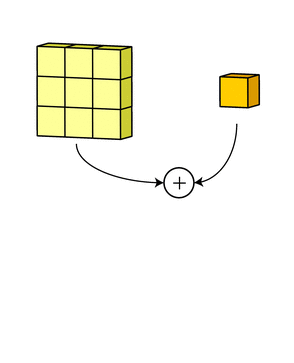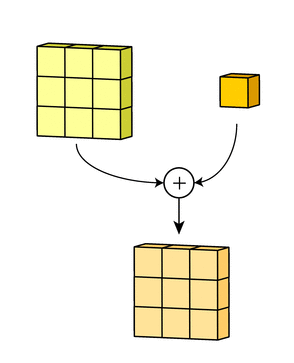
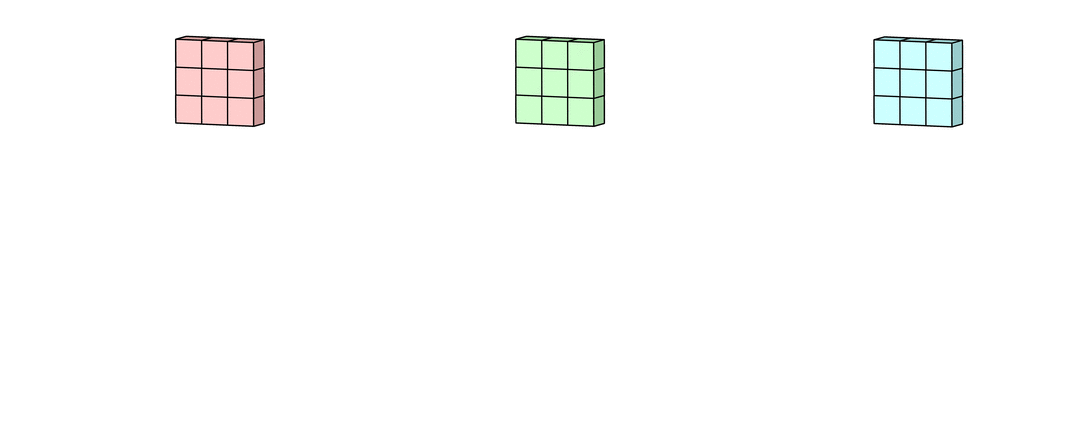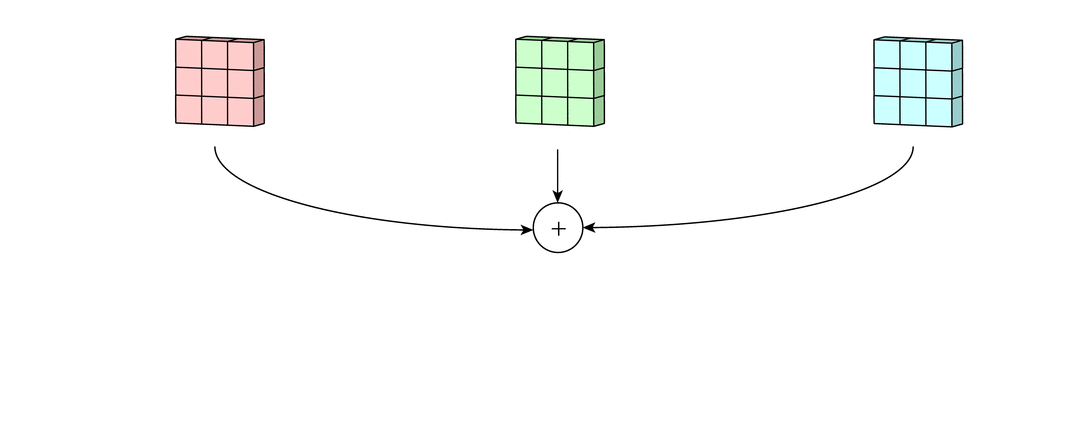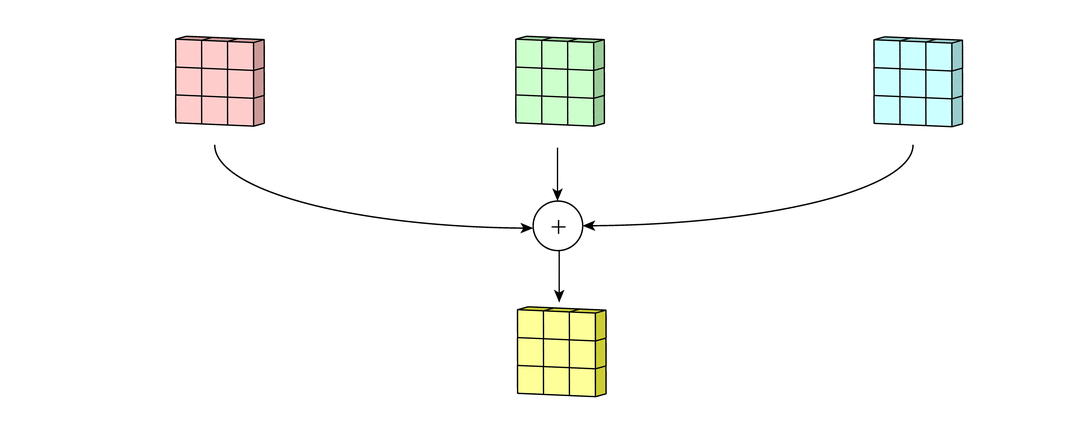 Add one bias term to get the final output channel
Add one bias term to get the final output channel
 In a convolutional layer
In a convolutional layer
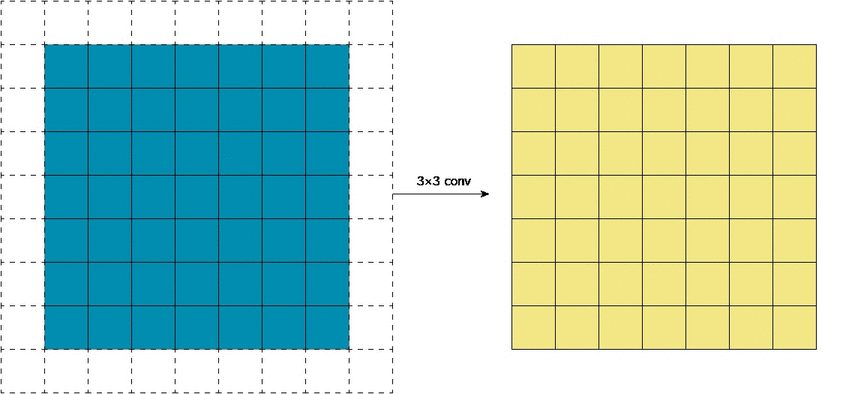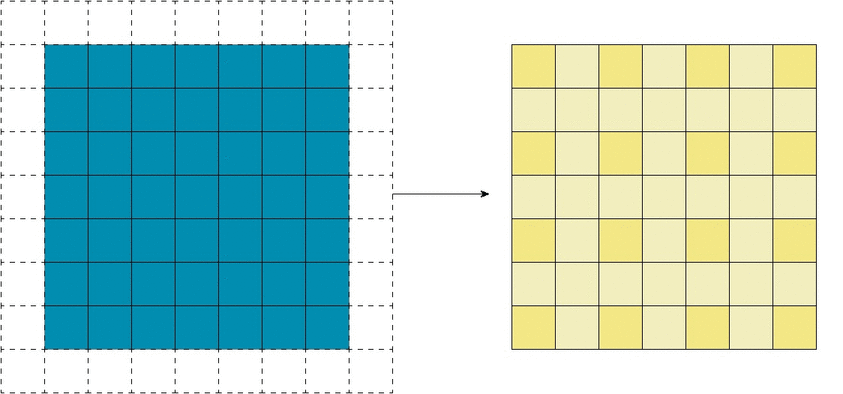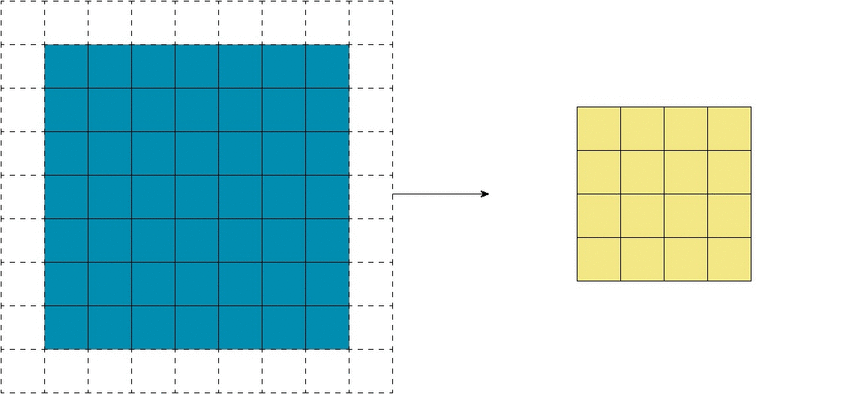
Padding convolution
Strided convolution
If we stack features from convolutional layers on top of each others, we can extract deeper, clearer features. But they’re still operating on small patches of the image; we can’t expand the receptive field yet.
That’s when we can use strided convolution: we only process slides a fixed distance apart, and skip the ones in the middle. From a different point of view, we only keep outputs a fixed distance apart, and remove the rest;
and if we apply a kernel on this output of the strided convolution, the kernel would have a larger effective receptive field.
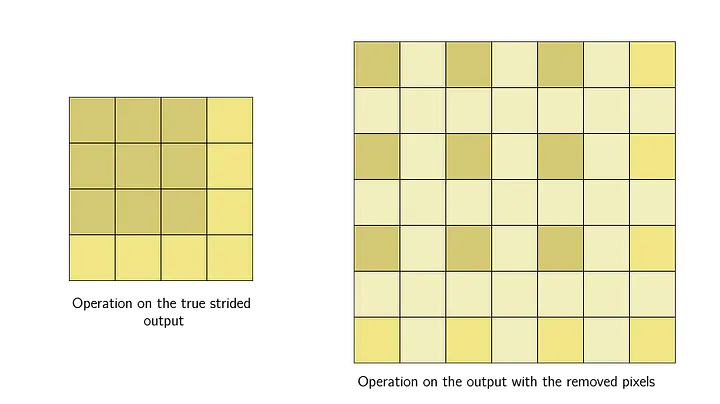 so that a neuron in the deeper layer takes input from a larger area of the previous layer
so that a neuron in the deeper layer takes input from a larger area of the previous layer
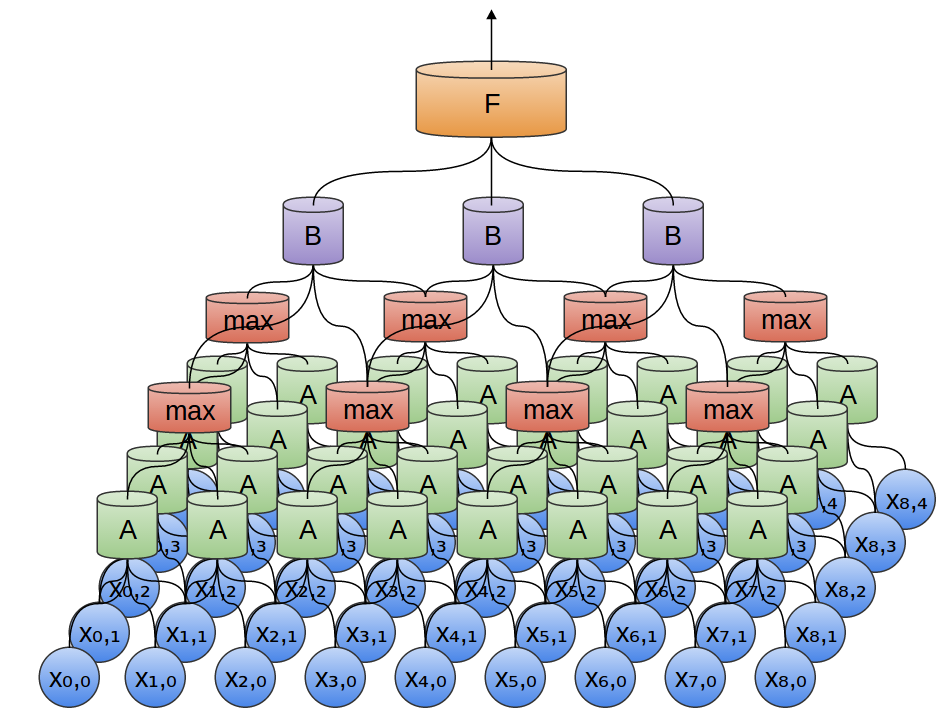
Pooling layer (Optional)
Reduce the amount of information by grouping nearby pixels together and keep only the most important ones.
Fully connected layer
We can feed the output of convolutional layer 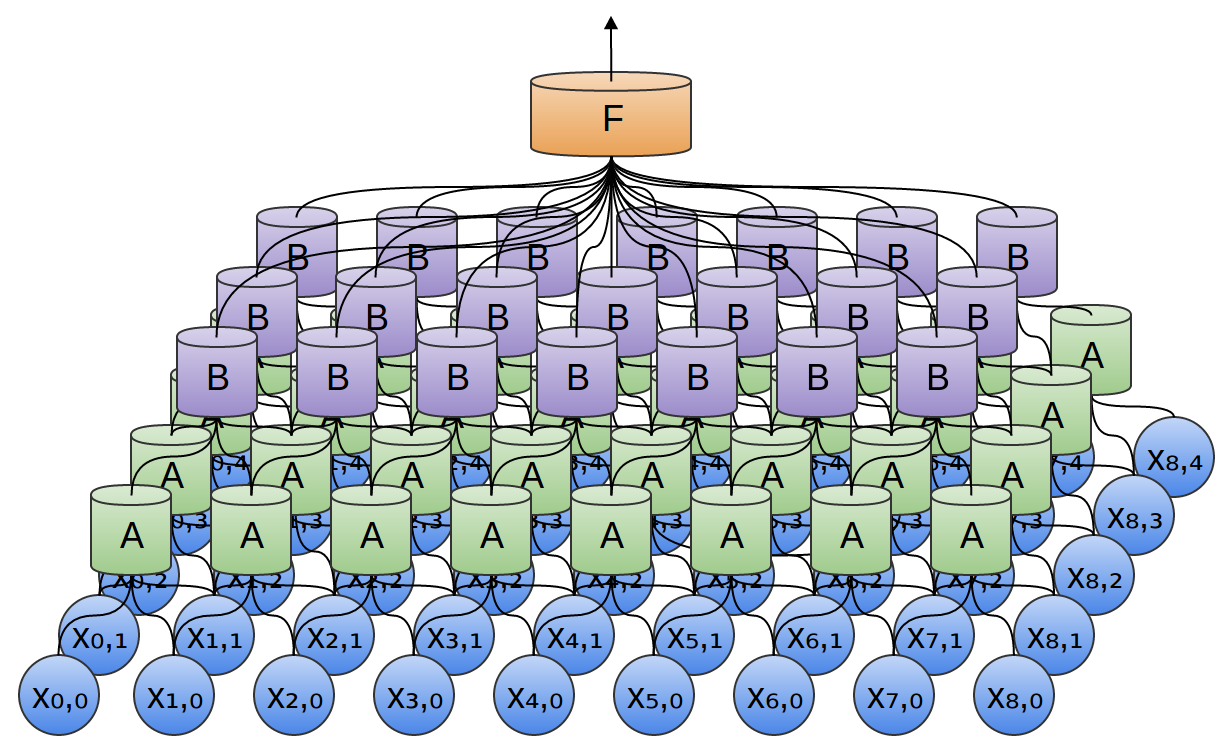
or pass it into the max pooling layer (to only take the maximum of features over a small patch), if we don’t care about the exact position of an edge, down to a pixel.
Output
- Final output: Result obtained after processing the input data through the layers of the CNN.
- Convolutional layer output: feature maps representing different learned features.
Intuitions
- convolution are still linear transformations
- Locality is okay for image: Unlike other types of data, pixel data is consistent in its order. Nearby pixels influence each other, and this information can be used for feature extraction. Kernels can detect anomalies by comparing a pixel with its neighboring pixels.
- tied weights: the same set of learnable parameters (weights) is used for multiple locations in the input data. This property exploits the assumption that the same feature (such as an edge or a texture) can appear in different parts of an image. Instead of learning separate weights for each location, CNNs share weights, reducing the number of parameters to optimize and improving generalization.