A confusion matrix is a graphical representation of how accurate a classifier is at predicting the labels for a categorical variable.
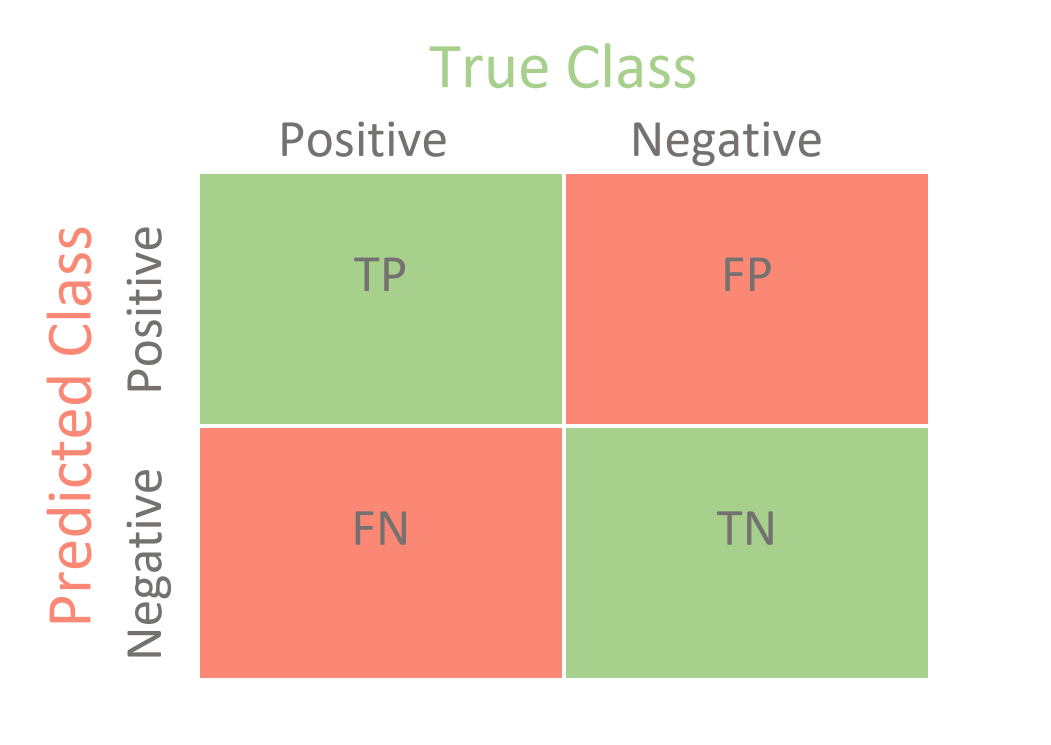
- True Positive:
- True Negative:
- False Positive = Type I error
- False Negative = Type II error
Usage
- Compare metrics mentioned between different types of ML algorithms
- The dimension of confusion matrix depend on the number of wanted categories of prediction. For example, if we want to predict whether a student is sleep-deprived, or sleeping enough or oversleeping, the matrix could be 3x3.
Type of metrics
Accuracy
Transclude of accuracy
Precision
precision
precision is the proportion of TRUE positives over all PREDICTED positives
Link to original
Recall / Sensitivity
sensitivity
recall, or sensitivity, as a classification metric, is the proportion of correctly predicted observations in one class out of all observations in that class. Or the ratio of TRUE positives out of all ACTUAL positives
This has a formula opposite of specificity
Transclude of specificityUsage
recall is important when we believe False Negatives are more important than False Positives (e.g. problem of cancer detection).
Link to original
- Out of survived passengers, how many did we label correctly?
- Out of the sick patients, how many did we correctly diagnose as sick?
Specificity
Transclude of specificity
F-beta
F-beta
score is the weighted harmonic mean of precision and recall. It’s a more generalized version of F1 score
is a factor that determines how many times more important Recall is than precision in the score.
- If
is close to 0, it skews towards precision - If
, it is F1 score - If
(a large number), it skews towards sensitivity Precision-Recall Tradeoff
precision = the proportion of true positives out of all positive predictions = TP / (TP + FP) Recall = the proportion of true positives out of all actual positives = TP / (TP + FN)
Link to original
- If False Negative is worse than False Positive (minimize Type II error), the model requires a high Recall, so that it could catch as many positive cases as possible. We should tailor our F-beta to incline towards Recall (
)
- Diagnosing sick patients
- Detecting malfunctioning parts in a spaceship
- If False Positive is worse than False Negative (minimize Type I error), the model requires a high Recall. We should tailor our F-beta to incline towards precision (
)
- Sending promotional material in the mail to potential clients (we don’t want to send to many people that won’t be interested)