(ML Specialization) (Code) ML Specialization regularization is a technique to penalize complexity of the models to prevent overfitting, by reducing the value/impact of parameters. This means it introduces more bias and lowers variance.
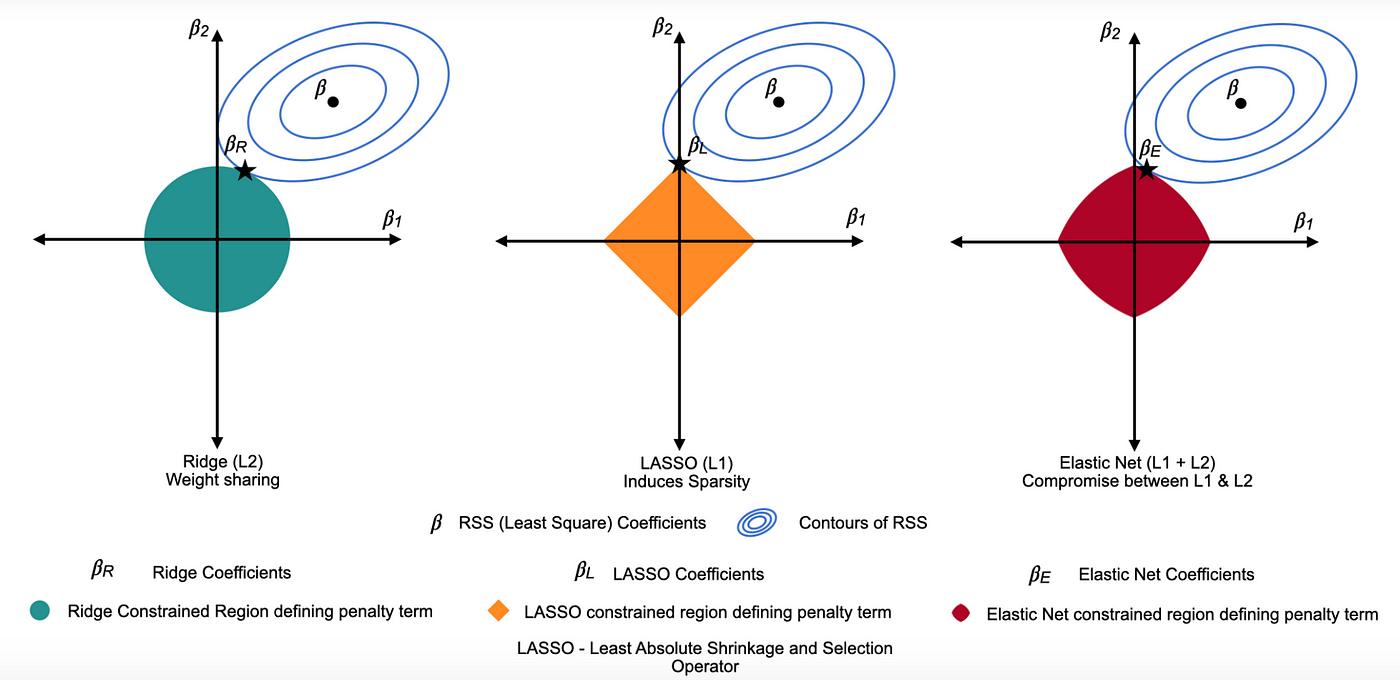
overfitting often comes from having too many parameters. There are generally two types of regularization: reducing the impact of parameters (Ridge) or zeroing the parameters (Lasso)
Types
(Regularization on Regression) (Interactive Visualizer)
- Lasso regularization: completely remove low-impact predictors
- Mathematically, it adds a penalty term to the cost function of regular regression, which is the sum of absolute value of coefficients multiplied by a regularization parameter
. - Lasso can shrink the slope to 0 and encourage such zero coefficients (visualization)
- Ridge regularization: minimize the impact of less relevant predictors.
- Mathematically, it adds a penalty term to the cost function of regular regression, which is the sum of squared coefficients multiplied by a regularization parameter
. - Ridge can only shrink the slope asymptotically to 0.
- Elastic Net regression: test Lasso regularization, Ridge regularization and a mix of both all at once
Cost function with regularization
regularization is added directly to the cost function
For example, mean squared error (cost of linear regression) with Ridge regularization:
: a vector of weights, a scalar-valued bias term : number of training examples : learning algorithm to fit a vector of features : training example in the dataset : regularization parameter. How much we want to shrink the impact of some predictors. The larger the more penalty. : number of features : weight parameter (to be penalized)
In practice, we might or might not penalize parameter
How to choose
(Source)
is inversely proportional to Variance Increasing the regularization parameter
reduces overfitting by reducing the size of the parameters. For some parameters that are near zero, this reduces the effect of the associated features. However, extremely large might lead to underfitting In contrast, a very small can leave overfitting unsolved.

- Try different values for
, each doubling the previous: - Minimize cost function with regularization, as we do normal cost function.
- Evaluate parameters
on the validation set
- Pick parameters that has the lowest validation error
- Report test error (or cross validation error as an estimate)
Why the procedure?
- When we start with small
, cost function with regularization on training set is increasing proportionately - We can then find
where the cost function of cross-validation set is the smallest (lowest validation error)
